Qwen-Image-Layered是阿里通义千问团队开源的图像分层生成模型,能够原生生成PSD格式的分层图像,为UI设计、广告制作等专业场景提供可编辑的AI图像生成方案,实现从"像素输出"到"设计对象输出"的范式升级。
关键字:Qwen-Image-Layered,分层图像生成,AI设计工作流,可编辑AI绘图,通义千问开源

官方地址
| 网址 | 说明 |
|---|---|
| Hugging Face | https://huggingface.co/Qwen/Qwen-Image-Layered |
重构专业设计工作流
从像素到设计对象的范式跃迁
当前AI图像生成领域的主流观点是,模型应以输出单帧精美图像为目标,设计师再通过Photoshop等工具手动分层、抠图、调整。Stable Diffusion和Midjourney等标杆产品均聚焦于像素级美学质量,却忽视了专业设计中最核心的 可编辑性 需求。这种"生成-手动拆分"的二次加工模式,成为AI融入商业设计流程的最大障碍。
Qwen-Image-Layered的核心价值在于原生分层生成技术。它并非在生成后处理分层,而是通过创新的层级感知注意力机制和结构化潜空间设计,在生成过程中直接建模不同视觉元素的层级关系,输出真正的PSD分层文件。每个图层可独立编辑、移动、调整样式,实现"一次生成,灵活修改"的设计工作流革命。这种从"像素思维"到"对象思维"的转变,让AI图像生成首次能无缝对接Figma、Photoshop等专业工具。
层级感知注意力机制
传统扩散模型在全局像素间计算注意力。Qwen-Image-Layered引入层级位置编码,将图层ID作为额外维度,使像素预测兼顾空间位置与图层归属。各图层特征在潜空间通道隔离、独立渲染后合成PSD,兼顾分离度与一致性。
结构化潜空间设计
传统潜空间将图像编码为扁平特征向量,Qwen-Image-Layered采用图层维度结构化,在潜空间中预分配独立子空间给不同图层。这种"分格存储"策略强制模型学习图层解耦表示,使任一格的修改不影响其他格,是后续独立编辑的架构基础。
技术突破与功能特性
精确的分层结构控制
模型采用分层Transformer架构,在潜空间中为每个视觉元素(如背景、主体、文字、装饰)分配独立的特征通道。生成时,模型不仅预测像素值,更预测像素的层级归属概率,确保元素边界清晰、遮挡关系合理。
分层Transformer架构
传统Transformer将图像视为扁平序列处理,Qwen-Image-Layered采用分层编码器-解码器结构:编码器端为每个图层分配独立Transformer分支,各分支共享自注意力层但拥有独立的前馈网络;解码器端引入跨图层注意力机制,在保持图层独立性的同时建模图层间遮挡关系。这种"先分后合"的架构强制模型学习图层解耦表示,使各图层在潜空间中保持正交,为后续独立渲染奠定基础。
层级归属概率
传统图像分割为像素分配硬标签,Qwen-Image-Layered在生成时为每个像素预测多分类概率分布,即属于各图层的概率值。这种软分配机制使模型能处理半透明、羽化边缘等复杂情况,在图层交界处生成平滑过渡,是实现RGBA图层精确分离和高质量透明通道输出的关键技术。
核心功能包括:
- 原生PSD输出:直接生成含图层、蒙版、混合模式的专业PSD文件
- 元素级控制:通过文本精确指定各图层内容、位置、层级顺序
- 智能图层命名:自动识别并命名图层(如"背景_渐变"、"主体_产品"、"文字_标题")
- 编辑友好性:图层间无像素粘连,支持无损移动、缩放、替换
专业场景优化
针对UI设计、电商海报、游戏UI等高重复性场景,模型内置了 设计系统意识 :
- UI套件生成:自动生成分层按钮、卡片、导航栏,符合设计规范
- 模板化广告:保留可编辑的文字图层和产品占位图层
- 游戏资产:分离角色、背景、特效图层,便于动画制作
使用方式与生态集成
多平台接入
Hugging Face体验:模型已上架Hugging Face,提供在线Demo和API接口,支持快速测试:https://huggingface.co/Qwen/Qwen-Image-Layered
本地部署:支持通过Transformers库加载,硬件要求与Stable Diffusion XL相当,单张24G显存显卡可流畅运行。官方提供详细的推理脚本和图层解析工具包。
插件生态:社区已开发Figma插件、Photoshop脚本,支持"文生分层图"一键导入设计工具,实现AI生成与人工精修的无缝衔接。
性能与质量
- 生成速度:1024x1024分辨率带5-8个图层的图像,平均生成时间约8-12秒
- 分层精度:图层边界交并比(IoU)达92%以上,文字与背景分离准确率超95%
- 编辑保真度:图层单独导出后重新合成,与原图PSNR>35dB,几乎无损
行业对比与优势
| 特性 | Qwen-Image-Layered | Midjourney V6 | Stable Diffusion XL |
|---|---|---|---|
| 输出格式 | 原生PSD分层 | 单帧PNG/JPG | 单帧PNG(需插件) |
| 图层编辑性 | 完整图层属性 | 不支持 | 有限支持(插件) |
| 元素控制 | 文本精确指定 | 文本模糊影响 | 需ControlNet辅助 |
| 专业工作流 | 直接对接 | 手动拆分 | 半自动化 |
| 开源协议 | Apache 2.0 | 闭源商业 | 开源但分层非原生 |
应用场景
UI/UX设计:快速生成登录页、 dashboard 分层稿,设计师只需调整细节而非从零绘制
电商运营:批量生成可编辑的商品海报,运营人员自行替换文案和商品图
游戏开发:生成分层场景概念图,美术团队分离元素进行进一步加工
广告创意:保留可编辑的Slogan图层,快速测试不同文案版本效果
品牌设计:生成符合VI规范的分层模板,确保视觉一致性
案例分享
图层分解基础能力

核心能力
给定一张图像,Qwen-Image-Layered可将其分解为多个RGBA图层
图层独立着色
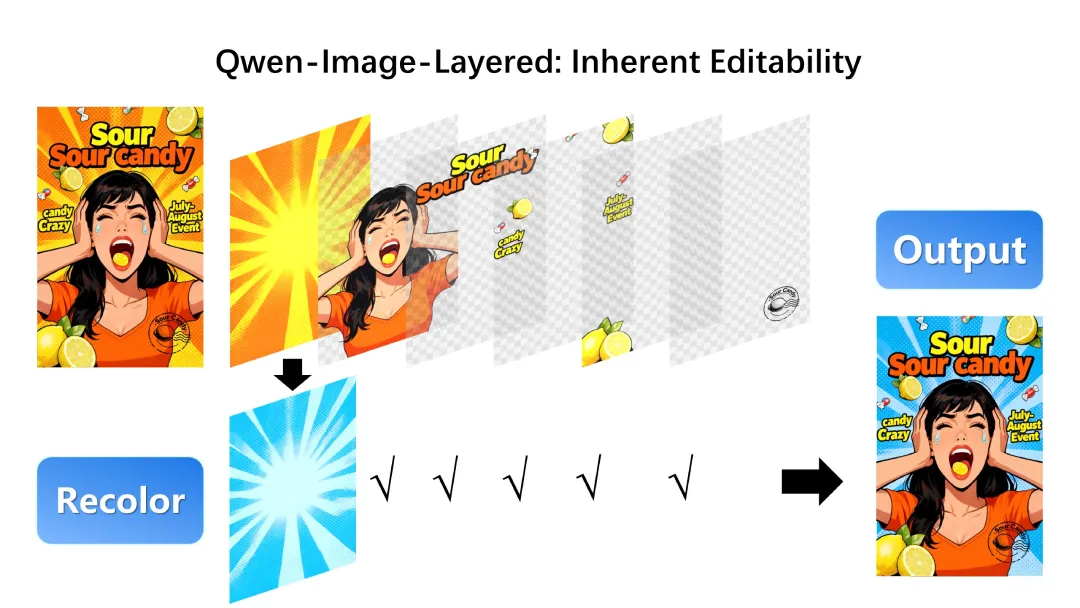
编辑操作
对第一层重新着色,其他图层内容完全不受影响
图层内容替换
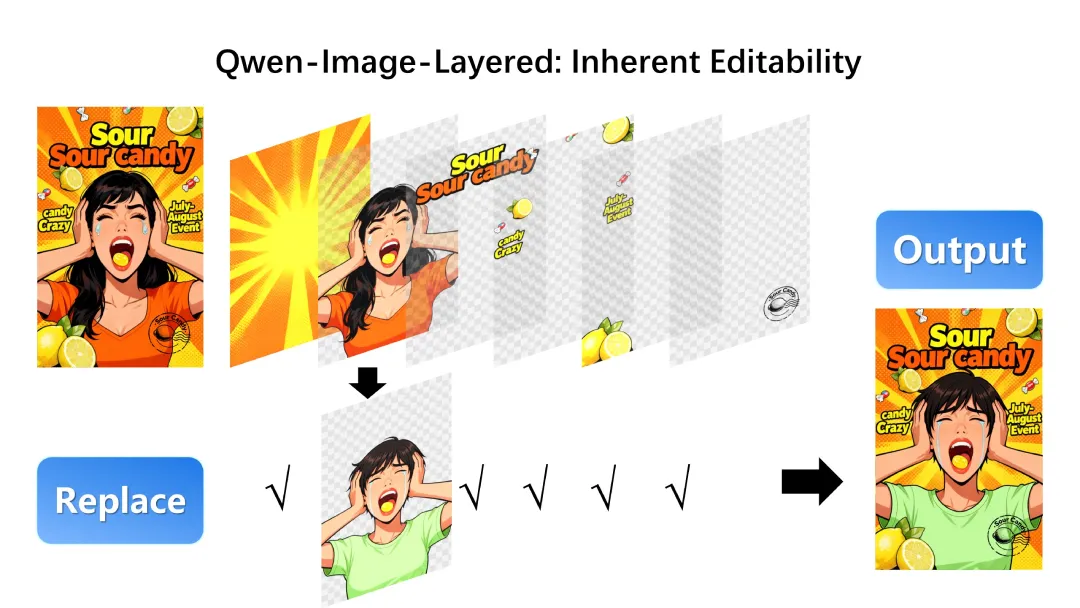
使用Qwen-Image-Edit编辑
使用Qwen-Image-Edit将第二层从女孩替换为男孩
文本图层编辑
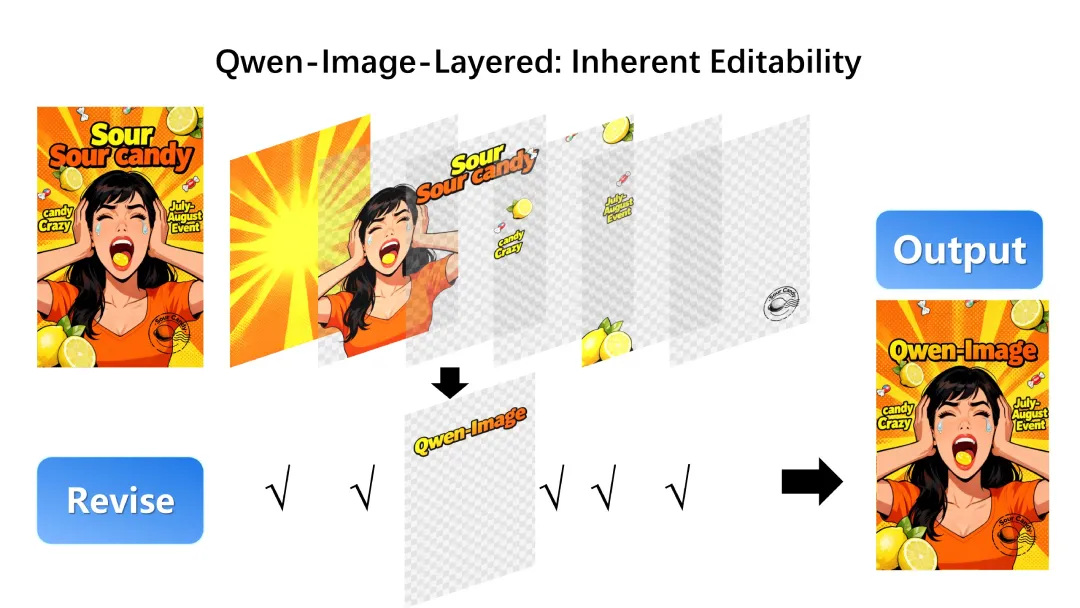
使用Qwen-Image-Edit编辑
使用Qwen-Image-Edit将文本修改为"Qwen-Image"
对象删除操作
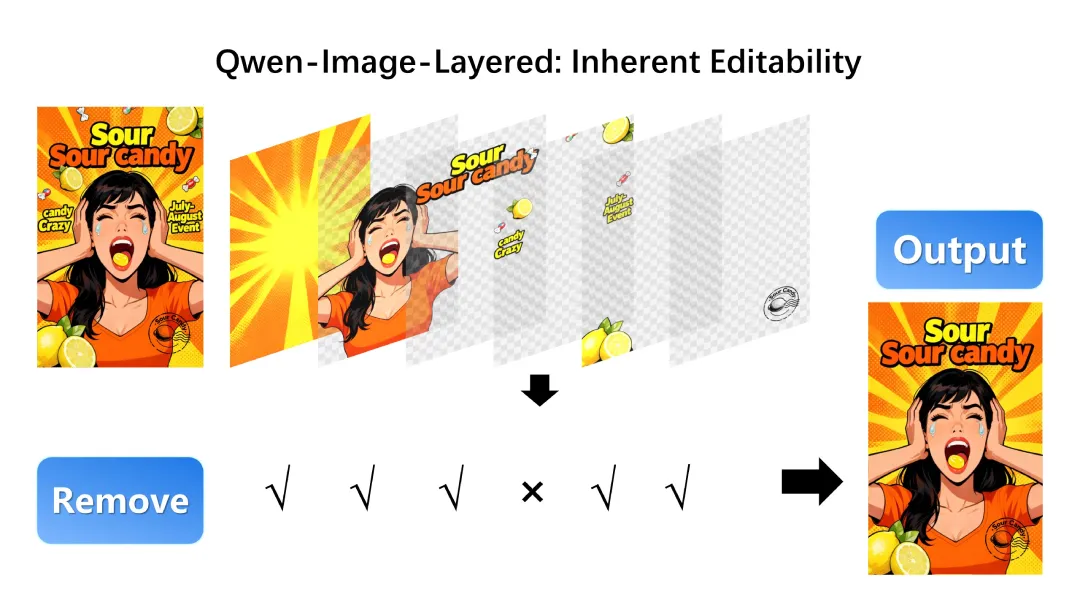
分层结构支持
分层结构支持干净删除不需要的对象
对象缩放不变形
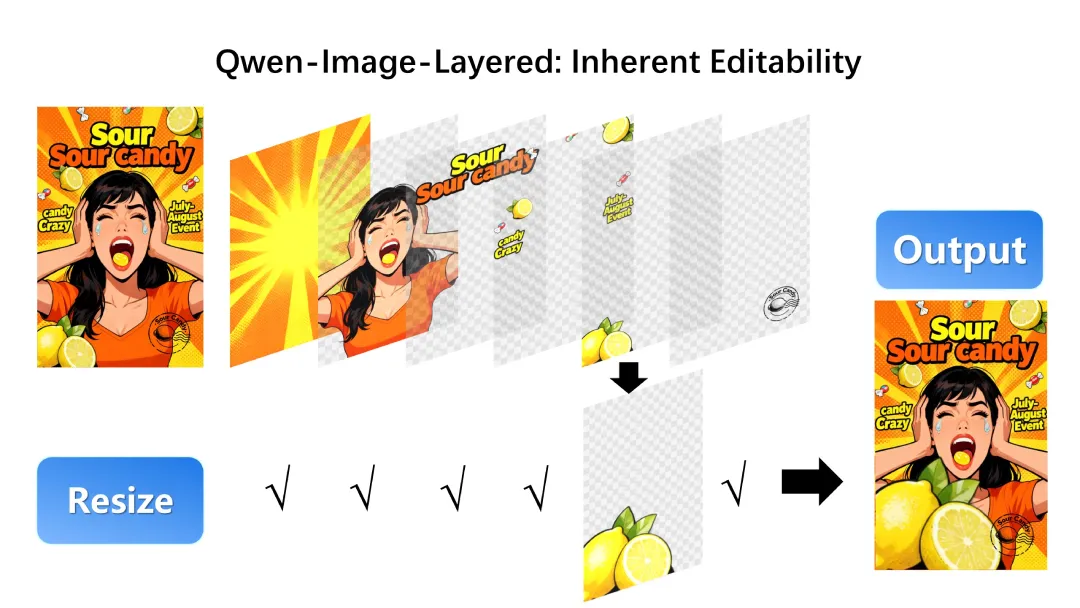
无损变换
调整对象大小时保持比例不失真
对象自由移动
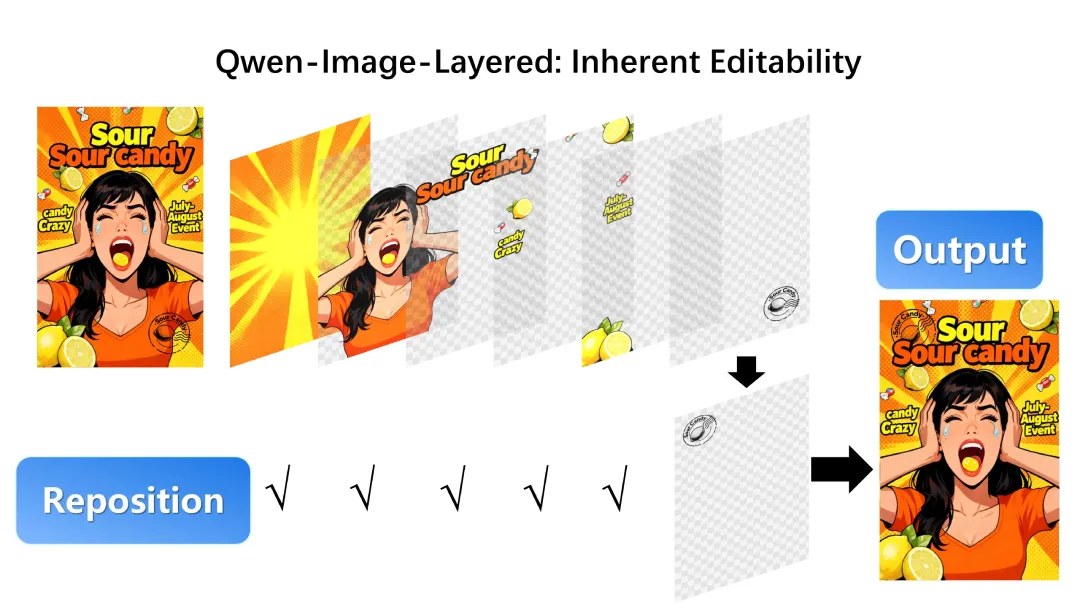
灵活 repositioning
分解后可在画布内自由移动对象
使用注意事项
模型目前对复杂光影交互(如玻璃杯后的折射)和极细线条(如发丝级分割)的分层效果仍有提升空间。建议生成后人工检查图层边缘,必要时使用传统抠图工具微调。
总结
Qwen-Image-Layered通过层级感知注意力机制,将AI图像生成从"美学竞赛"拉回"实用性革命",直接击中了专业设计流程的痛点。它不仅是技术架构的创新,更是设计思维的重构——让AI理解"图层"这一设计的基本语言。对于设计师,这意味着从重复劳动中解放;对于企业,这意味着营销素材生产效率的指数级提升。建议UI/UX团队立即尝试Figma插件集成,而AI研究者则应关注其结构化潜空间对多模态模型的启示。开源协议和商业友好的定位,使其有望成为设计AI化的基础设施。
扩展思考
当AI能原生理解"图层"后,下一个颠覆点是否是设计系统自动化?模型能否学习品牌规范,直接输出符合Design Token的分层组件库?更深层的挑战在于:多图层协同编辑(如调整背景自动优化主体光影)是否会成为下一代生成模型的标配?开源分层技术的普及,是否会倒逼Adobe将Firefly的核心能力免费化,以维持其设计生态的统治地位?